

Ever since AWS re:Invent, there’s been a lot of excitement around all the new products and services that Amazon Web Services launched in the last month or two. But I wanted to take the opportunity to write a little about a release from earlier last year which I don’t think gets enough attention: the T3 instance family.
The T3 family was announced as the successor to the previous-generation T2 family, which we wrote about shortly after they became available. The T3 family brings a lot of improvements and characteristic changes which make them even more powerful for a variety of workloads. We’ve been running T3 in production since launch, so here’s some of our thoughts.
More power, less cost.

The T3 instance family comes in exactly the same size types as the previous T2 generation, ranging from nano up to 2xlarge. Each instance type in the family is marginally cheaper than its T2 counterpart, and comes with marginally more power.
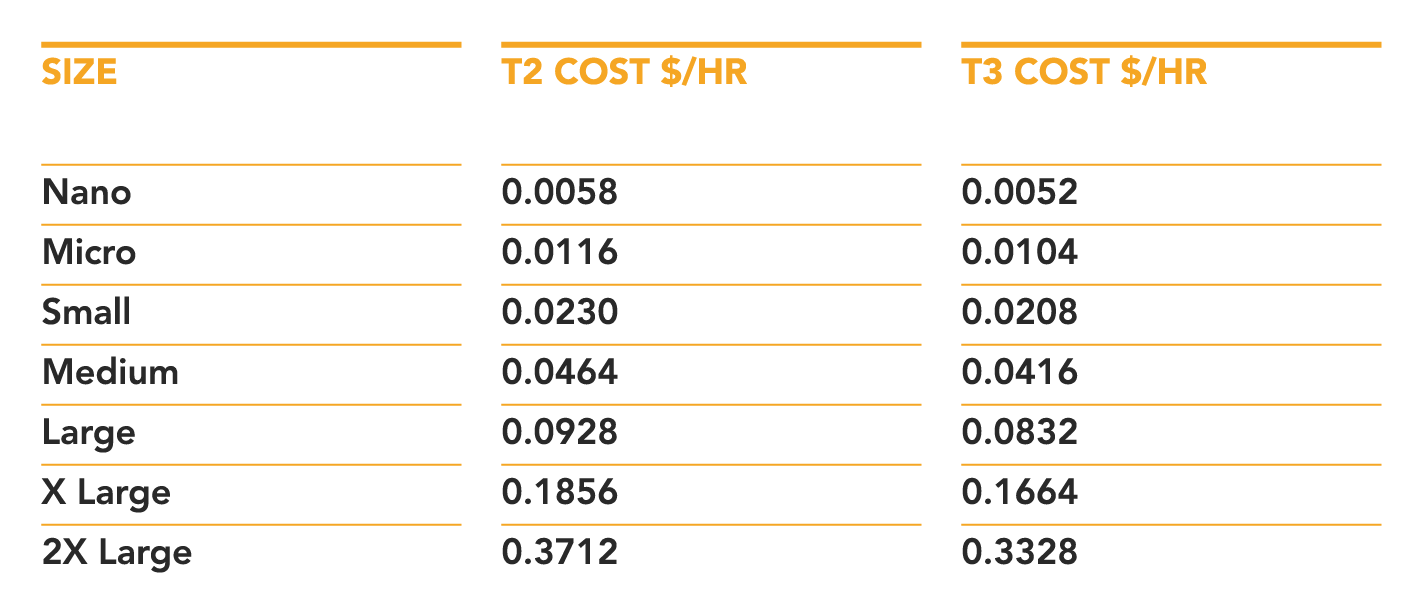
(all costs above for Linux on-demand in the us-east-1 region. Different regions have slightly different prices, but the comparison is roughly the same)
The T3 family is based on similar hardware to the M5 and C5 instance families, running on AWS’s “Nitro” stack with the ENA enhanced network driver and Intel Xeon Platinum 8000 series CPUs. This means right out of the box you’re getting more solid network and marginally faster per-core CPU performance than the equivalent T2 instance types.
With this in mind, the T3 instance family is already unquestionably better than the T2s – for the equivalent instance size you get faster CPU and better network, for less cost.
But wait, there’s more!

Something interesting in the comparison between T2 and T3 is that the smaller T3 instance types all come with two CPU cores. This means that before, if you were using the t2.medium instance type purely for its multi-core capabilities, these workloads could possibly run on a nano, micro or small instance type, if the job fits into the small RAM on the instance.

Another interesting point about T3 is that the nano, micro, and small instances get twice the baseline CPU usage of their T2 counterparts. I’m honestly not sure if this is a mistake on AWS’s part, but now the t3.small instance has the same CPU baseline as the t3.medium (compare with the t2.small where the t2.small has the same baseline CPU level per core as the t2.medium, but only half as many cores). This means that you effectively get double the baseline CPU time on T3 (so if you were running single-threaded workloads you now get double the capacity).
This means that if you were right-sizing your workloads on T2 based on CPU usage, when migrating to T3 you may be able to step down by one size if the memory requirements allow. For example, many of the workloads we were previously running on the t2.medium type, we’re now running on t3.small; if they were running on t2.small they’re now on t3.micro, and so on.
Not just for spiky workloads
In my post about T2 instances I mentioned a few workloads that were well-suited to the T2 instance type. These included spiky workloads such as email sending or CI servers.
But the T3 instance is not just for spiky workloads. Any situation where you’ll be running at a low average-utilisation per core are suitable for T3.
t3.small, a hidden gem if you need extra headroom

The quirk I mentioned earlier about the t3.small (and smaller) instance types means they’re now extremely cost-effective for running workloads where you need high CPU headroom. The t3.small instance has a comparable peak CPU performance to a c5.large, but at about 24% of the price (not including EBS, data transfer etc). That means, if you’re running at a low enough CPU level, you’re getting a ton of performance for a tiny price.
For example, most public-facing HTTP APIs need to be run with a certain amount of spare CPU capacity, or “headroom”, to account for unexpected fluctuations in request volume. How high this headroom is depends on the API in question, but for most of our APIs we try to run at around 50% average CPU usage. That is, we have 100% extra headroom so if traffic were to double instantaneously, we would be able to handle those requests without things breaking.
In fact, I’d go so far as to say, if you’re running any workload on c5.large at less than 60% utilization, it would be more cost-effective to use a bunch of t3.small instances, and you’d get even better headroom for handling fluctuations.
A concrete example
Here’s a solid example based on a migration we made earlier this year (we’ve made the numbers slightly nicer but the maths works out roughly the same). For a particular API we were serving requests from 10 c5.large instances, each running at an average 50% CPU utilisation. This works out to roughly 10 CPU core-hours per hour.
Now, we can take the same workload and serve those requests with t3.small instances. Since we want to stick to roughly the baseline allowance, we aim for roughly 20% utilisation. Working the numbers backwards this means that to get our 10-core load, we’ll need 50 CPU cores at 20%, or 25 t3.small instances.
So by migrating from c5.large to t3.small, we’re running 2.5x as many instances, but at 24% of the per-instance cost. That works out to an overall cost saving of around 29% (before accounting for things like EBS volumes). Plus since we’re running at 20% average utilisation, we now have roughly 400% headroom to handle unexpected spikes in traffic – a 4x increase on the equivalent workload run on C5. Win win!
An additional advantage of this is that by running more, smaller instances, services like this can be scaled up and down in smaller increments. Which means even more cost saving since it’s much easier to set Auto Scaling groups to the exact size you need.
Versatile for almost any workload

I genuinely believe the T3 instance type is the most suitable and cost-effective for almost any workload* (* that we’ve come across). Most workloads in our tech stack are CPU-intensive, but need to run with headroom to handle fluctuating traffic. And as we’ve seen, the t3.small instance type is excellent for that pattern.
There are obviously some usage patterns that don’t suit the T3 family:
- Long-running heavy calculation jobs where you need to run for a long time at maximum CPU performance (C5 or Z1 are best for this)
- Jobs that are highly sensitive to network performance (C5 or C5n have much better dedicated network throughput and latency)
- Jobs which require a lot of disk operations (M5 has better dedicated bandwidth to EBS for this)
- Databases or other workloads where CPU is very predictable and you can safely run at >70% utilisation without things falling over
We’re migrating a lot of our services to run on T3 – everything that previously ran on T2, but also several that were using C5 or M4 where it makes sense from a cost-saving standpoint.
Obviously even with all this in mind, there’s definitely no hard-and-fast rule that says what types are best for what workloads – the answer to the question “what instance type should I use?” is almost always “it depends” or “just try out a few different ones and see”. There’s plenty of resources out there to help with making that sort of decision – Cloudability recently wrote a great post comparing the relative merits of M5 and T3, and there are many others.
But wait, there’s more! … soon.

While writing this post, AWS announced the upcoming availability of the T3a instance family – essentially the same instance types as normal T3 but powered by AMD EPYC processors instead of Intel. These instance types have comparable performance for most workloads, but at an additional 10% cost saving. By the time you read this they may already be available, so definitely worth checking out and evaluating against all the other options.
How are you using T3 instances in your EC2 infrastructure? Are there even more use-cases that we’ve not mentioned? Let us know on Twitter!

